

หน่วยปฏิบัติการวิจัยและพัฒนาทรัพยากรมนุษย์ด้านความรอบรู้ทางดิจิทัลและการรู้เท่าทันสื่อ (DIRU) คณะนิเทศศาสตร์ จุฬาลงกรณ์มหาวิทยาลัย ร่วมกับ นักวิจัยจากคณะเทคโนโลยีสารสนเทศและนวัตกรรมดิจิทัล มหาวิทยาลัยเทคโนโลยีพระจอมเกล้าพระนครเหนือ โดยการสนับสนุนเงินทุนวิจัยจากกองทุนพัฒนาสื่อปลอดภัยและสร้างสรรค์ตามยุทธศาสตร์การรับมือกับข่าวปลอม
เปิดตัว ไทยดีไอแมชีน (THAI D.I. MACHINE) เว็บไซต์ตรวจสอบข่าวปลอม ให้ประชาชนทั่วไปสามารถคัดกรอง ตรวจสอบเนื้อหาข่าวปลอมได้ด้วยตัวเอง เพื่อให้การตัดสินใจก่อนจะแชร์ข่าวมีความถูกต้องมากขึ้น ช่วยชะลอการแชร์เนื้อหาข่าวปลอม โดยใช้ฟีเจอร์คัดกรองข่าวปลอม 5 ระดับ ผ่านเว็บไซต์ www.thaidimachine.org

รองศาสตราจารย์ ดร. พนม คลี่ฉายา หัวหน้าหน่วยปฏิบัติการวิจัยฯ DIRU คณะนิเทศศาสตร์ จุฬาลงกรณ์มหาวิทยาลัย เผยผลงานวิจัยการตอบสนองและการจัดการข่าวปลอมของประชาชน โดยสำรวจจากกลุ่มตัวอย่างประชากรจากทั้ง กรุงเทพมหานครและปริมณฑล รวมถึงทุกภูมิภาคทั่วประเทศ กว่า 1,120 คน
พบว่า มีผู้ใช้งานบนโลกอินเทอร์เน็ตถึง 51.5% ที่ได้รับแหล่งข่าวที่ไม่น่าเชื่อถือระบุไม่ได้ว่าเป็น ‘ข่าวปลอม’ ซึ่งมีเพียง 41.4% ที่สามารถระบุได้ว่าเป็น ‘ข่าวปลอม’ นอกจากนี้ยังมีการเปิดเผยอีกว่าช่วงอายุ 36-45 ปี เป็นวัยที่ไม่สามารถยืนยันข่าวปลอมได้มากที่สุด รวมไปถึงช่วงอายุ 8-20 ปี ที่มีการแชร์ข่าวโดยไม่ได้พิจารณาก่อนมากที่สุด และสิ่งที่น่าเป็นห่วงอีกเรื่องนึงคือ กลุ่มผู้สูงอายุไม่รู้ว่าจะไปหาแหล่งข่าวที่น่าเชื่อถือจากที่ไหน
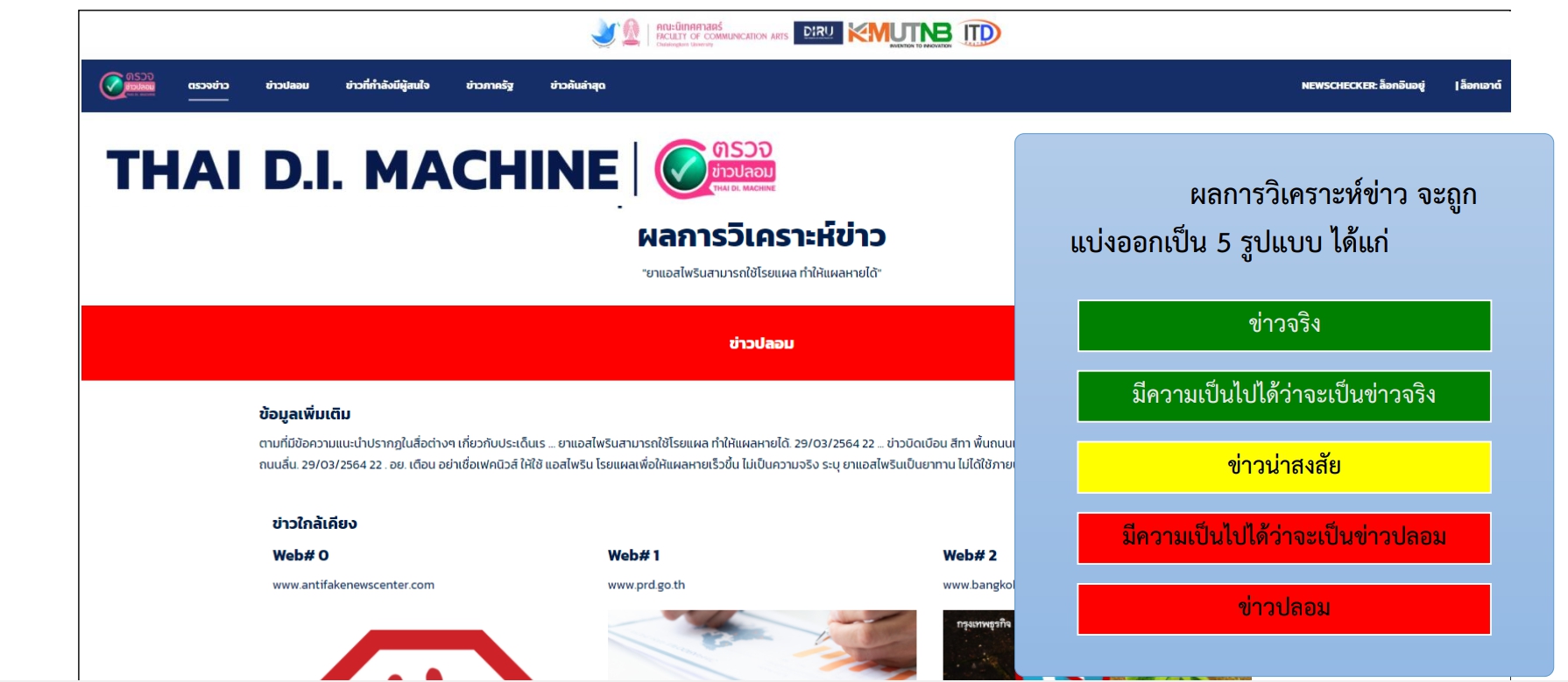
ด้วยเหตุเหล่านี้จึงเกิดเป็นการพัฒนาต้นแบบเว็บแอปพลิเคชันสำหรับการตรวจข่าวปลอม เพื่อรับมือกับบรรดาข่าวปลอมที่เกิดขึ้น โดยใช้หลักการการกรองข่าวด้วยวิธีการสืบค้นข้อมูลสารสนเทศ การประมวลผลภาษาธรรมชาติ และการเรียนรู้ของเครื่อง ให้สามารถตรวจวิเคราะห์ข่าวแบบอัตโนมัติ และแบ่งการวิเคราะห์ข่าวที่น่าสงสัยเป็น 5 ระดับ ได้แก่
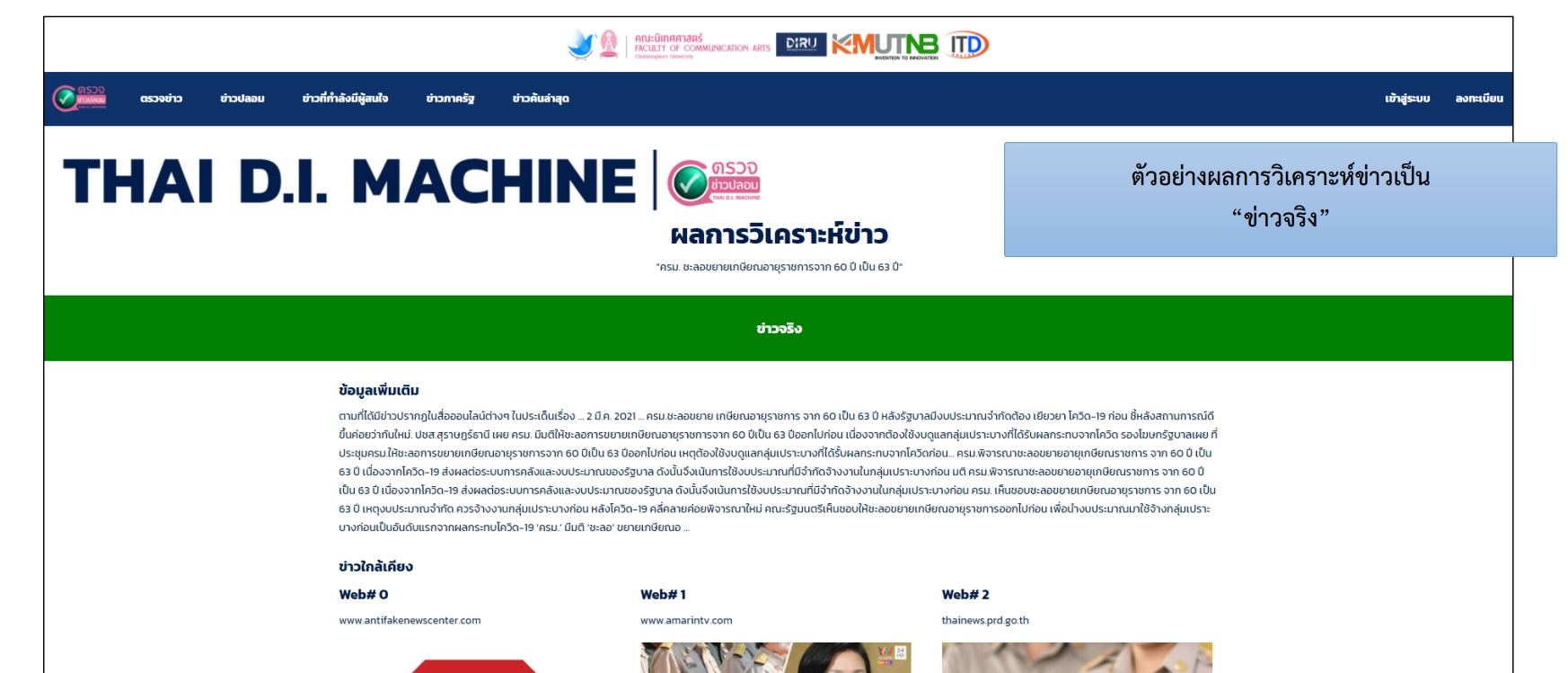
- ข่าวจริง – สีเขียว
- มีความเป็นไปได้ว่าจะเป็นข่าวจริง – สีเขียว
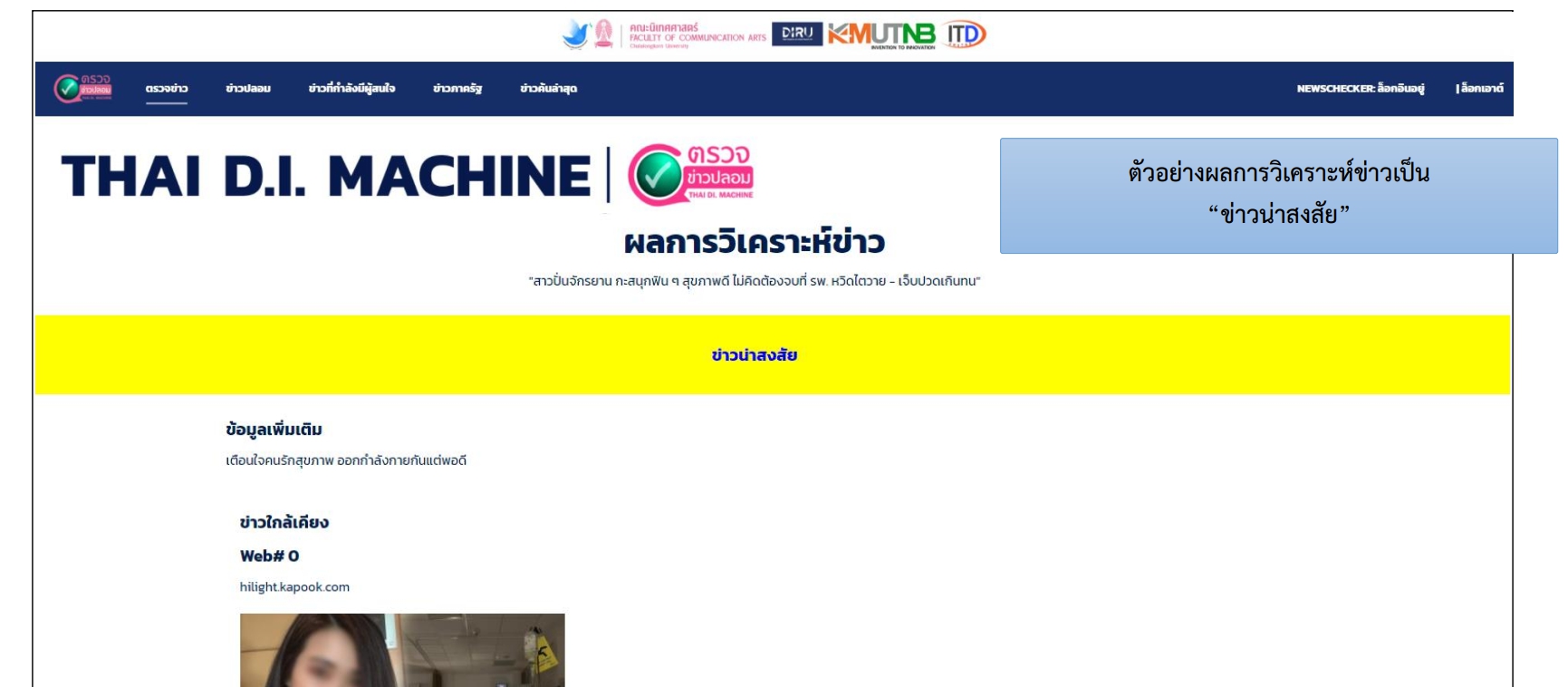
- ข่าวน่าสงสัย– สีเหลือง
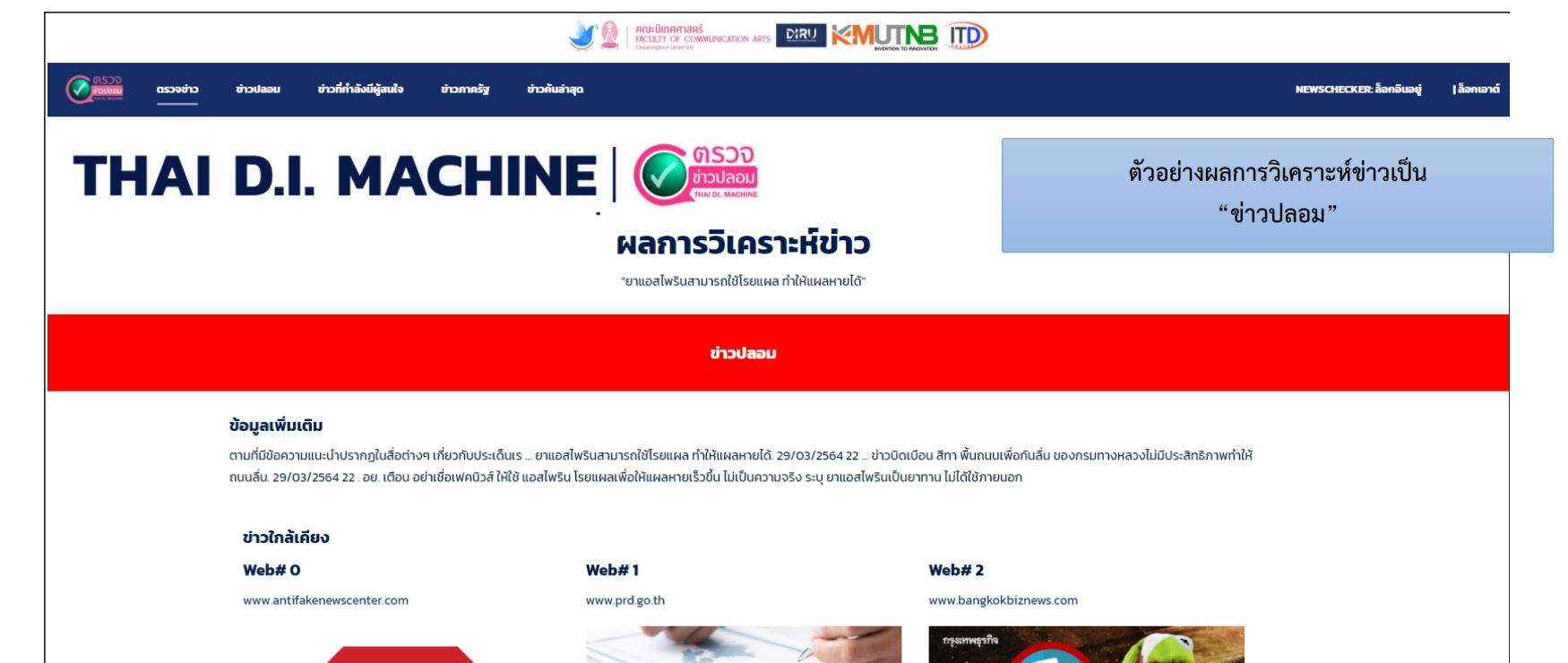
- มีความเป็นไปได้ว่าจะเป็นข่าวปลอม – สีแดง
- ข่าวปลอม – สีแดง
การพัฒนาระบบ THAI D.I. MACHINE
- สร้างระบบพื้นฐาน ใช้หลักการสืบค้นข้อมูล การประมวลผลภาษาธรรมชาติ และการเรียนรู้ของเครื่อง
- การเรียนรู้ของเครื่อง ประกอบด้วย
- Clustering
- Neural Network
- Naive Bayesian
- K Nearest Neighbor
- Rule-Based System / Expert system
- การพัฒนา Web Application
การทำงานของ THAI D.I. MACHINE
รองศาสตราจารย์ ดร.พยุง มีสัจ คณะเทคโนโลยีสารสนเทศและนวัตกรรมดิจิทัล มหาวิทยาลัยเทคโนโลยีพระจอมเกล้าพระนครเหนือ เผยกระบวนการวิเคราะห์ข้อมูลของระบบว่า โดยขั้นตอนแรกระบบจะรวบรวมข่าวจากแหล่งข่าวทุกที่ ไม่ว่าจะเป็น เว็บไซต์ เฟซบุ๊ก หรือทวิตเตอร์ เพื่อให้การประมวลผลธรรมชาติ วิเคราะห์คำ ข้อความ ประโยคต่าง ๆ จำแนกข่าวแต่ละรูปแบบ
หลังจากนั้นก็ค่อยใช้ระบบการเรียนรู้ของเครื่องแบบระบบผู้เชี่ยวชาญ (Expert System based Machine Learning) และใช้ฐานกฎหรือความรู้ (Rule Base or Knowledge) เป็นการจำแนกข่าว โดยระบบเชี่ยวชาญจะมีการจำแนกข่าวที่ฉลาดขึ้นเรื่อย ๆ ขึ้นอยู่กับจำนวนผู้เข้ามาใช้บริการเว็บไซต์ในการสืบค้น
ลำดับการทำงานอย่างละเอียดของ THAI D.I. MACHINE
- ระบบสำหรับรวบรวมข้อมูลขนาดใหญ่
- สถาปัตยกรรมฮาร์ดแวร์สำหรับข้อมูลขนาดใหญ่
- การติดตั้งซอฟต์แวร์ Apache Hadoop เพื่อรองรับการจัดเก็บข้อมูลขนาดใหญ่
- การวิเคราะห์ข้อมูลขนาดใหญ่
- การวิเคราะห์การแพร่กระจายข่าวทางสื่อสังคมออนไลน์
- การวิเคราะห์ข่าวใกล้เคียง
- สื่อออนไลน์ที่ใช้วิเคราะห์
- ข่าวปลอม และข่าวถูกต้องที่ใช้วิเคราะห์
- ประเด็นการวิเคราะห์เนื้อหา
- หน่วยการวิเคราะห์ (Unit of Analysis)
- เครื่องมือที่ใช้วิเคราะห์เนื้อหาข่าวปลอมและข่าวถูกต้อง
- การวิเคราะห์ และออกแบบระบบผู้เชี่ยวชาญ
- การวิเคราะห์ และการออกแบบโปรแกรมตรวจสอบข้อเท็จจริงข่าวปลอม
- ฐานข้อมูลที่ใช้ในการวิเคราะห์
- ฐานข้อมูลคำศัพท์
- การวิเคราะห์ และออกแบบกระบวนการเรียนรู้ของเครื่อง
- การพัฒนาโปรแกรมตรวจสอบข้อเท็จจริงข่าวปลอม
- การวิเคราะห์ และออกแบบระบบ
- การพัฒนา
- การทดสอบระบบ
การใช้งาน thaidimachine.org




ทิศทางต่อไปของ THAI D.I. MACHINE
ดร. พนม ยังเสริมต่อไปอีกว่า หลังจากนี้ทางทีมวิจัยก็ยังสานต่อการพัฒนาเว็บไซต์นี้ต่อไปเรื่อย ๆ ไม่ใช่แค่สำเร็จแล้วจบ ทางทีมวิจัยยังมีเป้าหมายที่จะพัฒนาฟีเจอร์ที่อาจจะไปแทรกกับ Search Engine ต่าง ๆ อีกด้วย
พิสูจน์อักษร : สุชยา เกษจำรัส